
There’s immense value in bridging the gap between technical details and practical applications, as it enables better distribution and reach of technologies. With this in mind, we’re launching a new blog series, “AI and Clarity.”
This series is designed for those who want to stay informed about enterprise solutions and explore how they can be leveraged to drive meaningful outcomes, regardless of their technical background.
While AI is increasingly multimodal, integrating text, image, and video processing, we’ll start with the fundamentals of AI for text. Join us as we set the stage for a deeper understanding of AI’s potential in the enterprise landscape.
Table of contents
Introduction
Artificial Intelligence (AI) took a giant leap forward on November 30, 2022, when ChatGPT was launched to the public—a day that’s already becoming a landmark in how we use AI in everyday life. With all the hype around Large Language Models (LLMs), it’s a good time to step back and understand how Natural Language Processing (NLP) has evolved over the years.
In this blog, we’ll break down the different NLP techniques, and their relevances up to LLMs and ChatGPT.
What is Natural Language Processing (NLP)?
Natural Language Processing encompasses all techniques that allow computers to interpret, manipulate, and comprehend human language.
What kind of tasks can I do with NLP?
- Search
- Clustering
- Data Extraction
- Classification – sentiment analysis, spam detection etc.
- Generation – translation, question answering etc.
For the computer to understand text they must be represented as numbers (known as vectors/embeddings). Some representations are implicitly learnt while learning to perform the task while others are independent techniques and can later be used to perform any task. Let’s look at their differences.
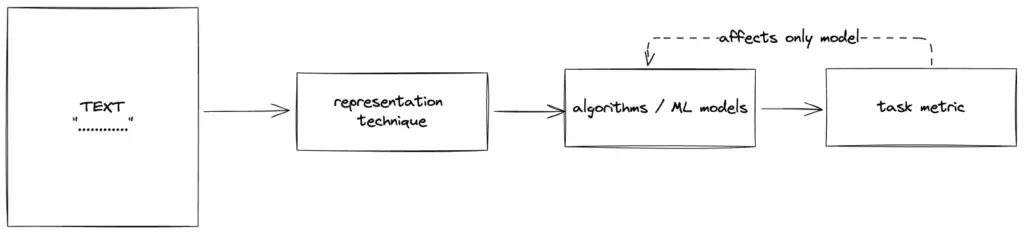
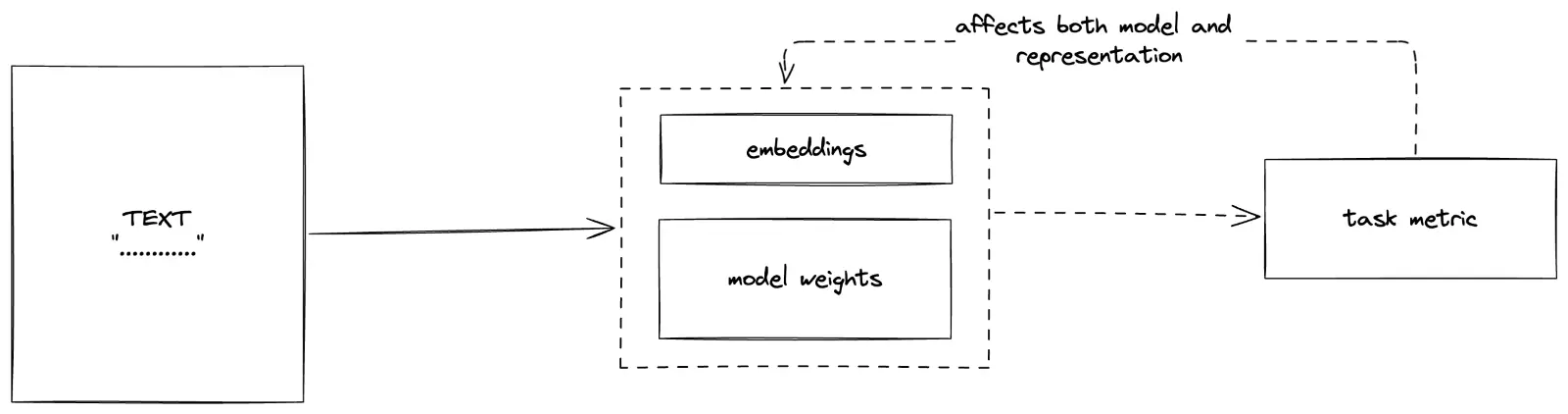
Task Agnostic vs Task Specific representation
| Task Agnostic | Task Specific |
| Can later be used for any purpose | Mostly based on deep learning, learn representation and perform the task together |
| The task at hand does not affect the representation and the representation technique can be swapped | Representations learnt for one task may not perform well for another |
| They could be used as input data to train ML/DL models, used to search or perform clustering | The representations are learned along with model weights and are driven by the task at hand |
NLP Timeline
We take a look through the timeline to see how NLP techniques have evolved over time to the 2020s. It started with a simple Task Agnostic Bag of Words.

Bag of Words model is one of the simplest and earliest methods for text representation in NLP. It captures the essence of a document with only the frequency of words appearing in the document, without regard to their order or context.
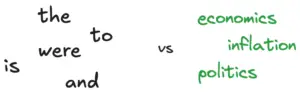
Improvement: TF-IDF (Term Frequency Inverse Document Frequency) improves on Bag of Words by assigning weights to words. A keyword like “inflation” in a document is more informative than words “the”, “is” etc. as they appear in most documents.
Technical: TF-IDF gives more weightage to words that appear less frequently across documents and vice-versa i.e the importance factor is inversely proportional to the number of documents the word appears in.
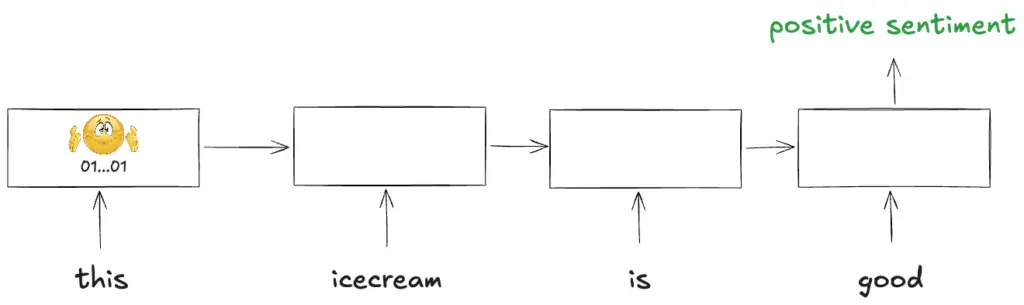
Improvement: RNNs as opposed to word2vec craft representations specific to the task using deeper networks and use the context of all the earlier words allowing them to perform better.
Technical: They recursively act one step (character, sub-word or word etc.) at a time using the same network weights at each step ingesting the new word’s meaning into the context and passing it on which gives them their name. They predict for each step or have one final prediction at the end.
Improvement: LSTM (Long Short Term Memory) and GRU (Gated Recurrent Unit) are variants of RNN that overcome the deteriorating performance and training issues RNNs have as they forget earlier parts of longer texts.
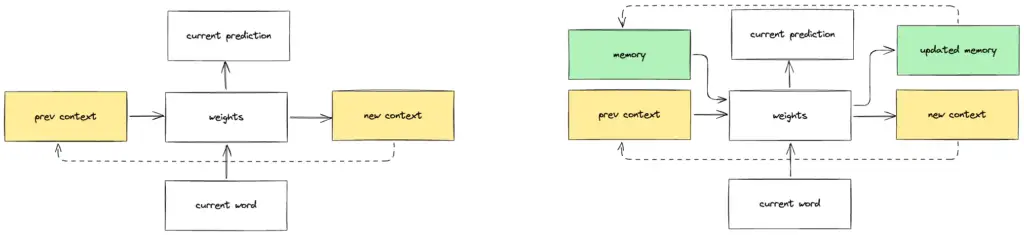
Technical: LSTMs use more parameters with more pathways for information to be propagated while choosing to remember and forget when necessary. This allows necessary information to be retained over longer texts.
Improvement: Previous methods don’t account for documents’ meaning and treat similar words as unique. Word2Vec is a neural network based technique to create word representations which allows measurement of similarity between words. So words “king” and “emperor” will not be treated as completely different words.
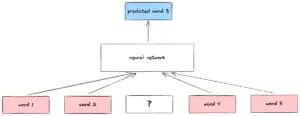
Technical: The 2 common techniques under this paradigm are
- CBoW (Continuous Bag of Words) – a neural network tries to predict the missing word given the words around it
- SkipGram – a neural network, given a word, tries to predict the words around it
Improvement: Seq2seq are DL models built using RNN blocks (and variants) but structured to generate text of arbitrary length.
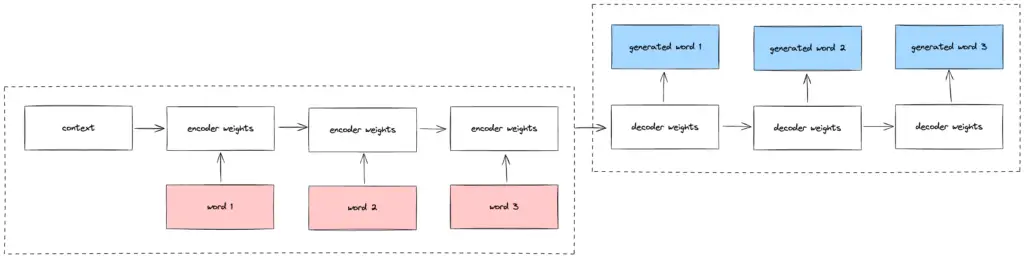
Technical: seq2seq model consists of an encoder and decoder. Encoder takes in the input text and provides a context to the decoder which uses the condensed information to generate the output text.

Improvement: The previous models performed poorly on long texts since they process one word at a time and tend to forget earlier seen information. The cornerstone of transformer model, attention mechanism, was introduced as an add-on for seq2seq models to combat this forgetting.
Technical: Attention allowed models to weigh and procure information from the entire input text instead of the sequential nature of the RNN family of models, improving the contextual awareness of the models.
Improvement: With enough time people figured “Attention is all you need” i.e. we can do away with RNN components completely and solely use just the attention mechanism to get better performance. This was the seminal paper that continues to transform the AI landscape.
![]()
Technical: The paper shows that the BLEU score for translation is better than the best seq2seq models at similar compute and memory requirements. Also to note transformers are highly parallelizable over RNNs as the latter is of sequential nature. You can notice how the original encoder-decoder structure from seq2seq has been retained here. This spawned a lot of architectures of which 2 of them stood the test of time – BERT and GPT.
 Improvement: Built by Google, BERT and its variants (RoBERTa, distillBERT) are the backbones of all predictive NLP tasks today such as sentiment analysis, NER etc, replacing LSTM based models. BERT embeddings are also a more powerful alternative to TF-IDF and word2vec embeddings, with it’s ablility to capture semantic meaning at a much deeper level and longer contexts.
Improvement: Built by Google, BERT and its variants (RoBERTa, distillBERT) are the backbones of all predictive NLP tasks today such as sentiment analysis, NER etc, replacing LSTM based models. BERT embeddings are also a more powerful alternative to TF-IDF and word2vec embeddings, with it’s ablility to capture semantic meaning at a much deeper level and longer contexts.
Technical: BERT is a large encoder only transformer model (only the left part from the figure) trained to predict missing words in sentences similar to word2vec but over larger context. It was also trained to predict if 2 given sentences are consecutive in nature or not. This allows BERT to understand individual words as well as continuity across text.
Improvement: OpenAI formed in 2015, initially were working Reinforcement Learning algorithms, but in 2018 they released a significant paper titled “Improving Language Understanding by Generative Pre-Training” which introduced the GPT. GPT and its variants are the backbones of all generative NLP tasks today such as summarization, QA, translation etc.
Technical: It is a large decoder only transformer model (only the right part from the figure) trained on generating the next word of the text.
NLP Techniques Cheat book
| Technique | Created by | Adoption | Use cases | How to use |
| Bag of Words | NA | NA | simple search, establish baseline | simple code |
| TFIDF | Karen Jones | used in Elastic Search for search | search, classification, clustering etc. | NLTK, SpaCy |
| Word2vec | NA | simple NLP models, establish baseline | pre-trained embeddings, custom trainable | |
| RNN | NA | NA | simple NLP models, establish baseline | pre-trained models, custom trainable |
| LSTM | Staudemeyer | used to be building block of SOTA models before transformers | models for data specific cases – stock market, signals etc. | pre-trained models, custom trainable |
| Seq2seq | Ilya et al. | previously used in Google Translate | models for data specific cases – stock market, signals etc. | pre-trained models, custom trainable |
| BERT | currently used in Google Search | SOTA for search, classification, clustering etc. | pre-trained models, custom trainable | |
| GPT | OpenAI | powers ChatGPT | SOTA for translation, summarization, QA etc. | pre-trained models are advisable |
Conclusion
The intersection of technology and business strategy is where real innovation happens. We shall recognize how these tools can empower executive and product decisions to enhance our organization’s capabilities.
In future posts, we’ll continue to break down complex ideas and provide actionable insights. We aim to help you make informed choices that align with your unique needs and goals.
References
Efficient Estimation of Word Representations in Vector Space, https://arxiv.org/abs/1301.3781
LONG SHORT-TERM MEMORY, https://www.bioinf.jku.at/publications/older/2604.pdf
Sequence to Sequence Learning with Neural Networks, https://arxiv.org/abs/1409.3215
Neural Machine Translation by Jointly Learning to Align and Translate, https://arxiv.org/abs/1409.0473
Attention Is All You Need, https://arxiv.org/abs/1706.03762
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, https://arxiv.org/abs/1810.04805
Understanding searches better than ever before, https://blog.google/products/search/search-language-understanding-bert
Language Models are Few-Shot Learners, https://arxiv.org/abs/2005.14165
Introducing ChatGPT, https://openai.com/index/chatgpt